Word2Vec
Source: Word2Vec Tutorial - The Skip-Gram Model
Consider a NN: Input a word, output others' word's probability that occur nearby the word:
Train Data:
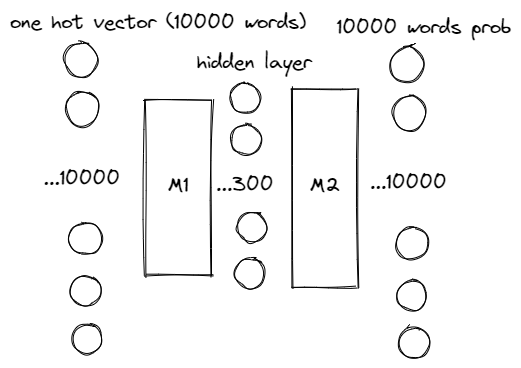
Matrix M1 shows the "feature" of 10000 words. Each word has 300 features.
Word Embedding
I eat apple
I -> [1, 0, 0]
eat -> [0, 1, 0]
apple -> [0, 0, 1]
--> [
[1, 0, 0],
[0, 1, 0],
[0, 0, 1]
]Attention
Good article: Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)